
Até onde a Inteligência Artificial pode ir?
A Inteligência Artificial teve, até o momento, um histórico repleto de estudos, implementações de sucesso e casos demonstrando grande risco e perigo para determinados grupos.
Conforme suas aplicações e o conhecimento da população sobre a IA crescem notavelmente, momentos do futuro próximo tendem a estar mais atendidos por sistemas de Inteligência Artificial do que o alto volume já experimentado na atualidade.
A IA que temos hoje, há tempos já faz parte da mecânica de jogos digitais, das redes sociais, de projetos de robôs autônomos e carros que se dirigem sozinhos, de sistemas de reconhecimento facial e reconhecimento de voz, da previsão do tempo para antever graves eventos climáticos, dos sistemas financeiros para detecção de fraudes e recomendação de investimentos, da otimização nas redes de distribuição de energia elétrica, da previsão de diagnósticos médicos e de muitos outros contextos.
Cada um desses contextos se dirige para cenários mais eficientes para as necessidades da sociedade graças ao avanço dos estudos e desenvolvimentos com a tecnologia de Inteligência Artificial.
Mais do que isso, o trajeto que estamos percorrendo com o estudo, o desenvolvimento e o uso prático de Inteligência Artificial nos leva a situações com impactos mais extremos, tanto positivos quanto negativos, cujos resultados e consequências dependem não só da tecnologia, mas também das decisões políticas, empresariais das grandes indústrias e dos conceitos de ética de cada nicho social.
Até alcançarmos esses variados objetivos, primeiro precisamos compreender de onde surgiu tal conjunto de tecnologias e como se dá o seu funcionamento.
Nascendo basicamente em ramos mais exclusivos como os ramos acadêmicos e militares, a Inteligência Artificial alcançou, ao longo das décadas, impacto por meio de soluções nas mais diversas áreas da medicina, da educação, do design gráfico, da música, da programação de aplicativos, do agronegócio e muitas outras.
A tecnologia e as informações adquiridas, construídas e compartilhadas pela humanidade ao longo dos anos nos permitiu expandir e organizar diferentes bases de conhecimentos generalistas e especialistas que se continham apenas na mente humana e nos livros, para embutir em bases digitais permitindo o uso por parte dos sistemas de Inteligências Artificiais que construímos.
Essas IAs já evoluíram por um longo caminho. Cada vez mais conhecedoras dos variados dados à disposição da humanidade, as Inteligências Artificias têm como finalidade aprender com esses numerosos dados e, então, nos apoiar, usando a sua inteligência, a resolver uma longa variedade de problemas, em uma alta velocidade e com níveis maiores de precisão. Contudo, sua chamada “inteligência” só poderá ser de fato valiosa ou minimamente adequada a depender do que nós mesmos conhecemos e permitimos ensinar às Inteligências Artificiais.
Diferentemente de qualquer oráculo ou fonte natural e onisciente de sabedoria e percepção, as ferramentas de Inteligência Artificial são construídas para nada mais, nada menos, tentar replicar a inteligência natural do ser humano e, em certos casos, superá-la onde é considerado necessário, com base nos modelos e nos dados que ele permite a ela. E essa superação já está atingindo diferentes tarefas e complexos contextos de nosso meio atual.
Ainda que muitas pessoas estejam apenas começando a se familiarizar de forma massificada com as novidades da área de Inteligência Artificial com aplicações presentes em seu dia a dia, e ainda que as soluções atuais estejam sendo cada vez mais impactantes para diferentes ramos do mercado, chegando a situações mais valiosas ainda no futuro, como iremos abordar, esse conceito da ciência da computação advém de um século anterior ao que vivemos hoje.
Origem
Em termos de origem documentada, Alan Turing, considerado o “pai da computação”, descrevia por volta das décadas de 1930 e 1940 uma “máquina de computação abstrata”. Mais especificamente no ano de 1948, o matemático e injustiçado cientista da computação descreveu em seu estudo intitulado Intelligent Machinery, posteriormente publicado na revista Mind, diversos conceitos centrais relacionados ao que hoje chamamos de Inteligência Artificial.
Esses conceitos envolviam analogias computacionais ao cérebro humano e uma máquina que pudesse aprender com a sua experiência, com a possibilidade de deixar a máquina alterar suas próprias instruções, fornecendo os mecanismos para tal.
Posteriormente, com um objetivo mais amplo e detalhado, foi organizado na universidade americana de Dartmouth um workshop de pesquisas e ideações durante o verão de 1956, usando pela primeira vez nas documentações o termo “Inteligência Artificial”.
O projeto contou com dezenas de pesquisadores e participantes do ramo da tecnologia, incluindo um dos organizadores principais, o professor John McCarthy, cunhado como um dos “pais fundadores da Inteligência Artificial” da forma que temos hoje.
De acordo com um dos parágrafos escritos na proposta do workshop, o estudo se baseava “na ideia de que todo aspecto de aprendizado ou qualquer característica da inteligência consegue, por princípio, ser tão precisamente descrito que uma máquina pode ser criada para simulá-la”.
Os mais de 40 envolvidos abordaram temas como aleatoriedade e criatividade, redes neurais, computadores automáticos e melhoria automática aplicada nessas máquinas por meio delas próprias com base na inteligência que elas adquirissem.
E essas propostas se provaram corretas com o passar dos anos e os desenvolvimentos que foram acontecendo para testá-las e cumpri-las.
O próprio professor John McCarthy que foi um dos organizadores da conferência de Dartmouth em 1956 fez as primeiras implementações no ano de 1958 da linguagem de programação LISP, umas das primeiras linguagens de programação eficiente a ser usada de forma ampla na construção de algoritmos para sistemas de Inteligência Artificial.
Contando com inúmeras pesquisas acadêmicas e desenvolvimentos demandados pelas necessidades do mercado, a Inteligência Artificial foi evoluindo na quantidade e na qualidade de sistemas, linguagens de programação e algoritmos que temos até hoje, incluindo na variabilidade de situações e aplicações para diferentes áreas do mercado.
Qualquer área que tenha um grande volume de dados conhecidos ou desconhecidos e que precisaria de um grande empenho da Inteligência natural do ser humano pode ser apoiada pelo uso de sistemas de Inteligência Artificial que tentam replicá-la e otimizá-la, ainda que nem todas elas precisem chegar a esse ponto ou compensem o uso de tais ferramentas.
Funcionamento
Usando como exemplo de análise o que a capa da edição do dia 20 de novembro de 2023 da revista norte-americana The New Yorker nos mostra, vemos uma exemplificação satírica — talvez até crítica em excesso — de como a Inteligência Artificial funciona em alguns modelos, da mesma forma que vemos como essa Inteligência Artificial pode não ser tão inteligente assim, pelo menos não em relação ao que queremos em certas situações e ao que esperamos obter com ela.

Há indicações certas e erradas sobre a IA nessa bela capa ilustrada.
Para sua surpresa (ou não) é basicamente assim que muitos modelos de IA funcionam.
Representada por um robô humanoide, a Inteligência Artificial, vendo que há alguns papéis amassados sobre uma mesa, e uma pilha de papéis em branco próxima a um lápis de frente a uma pessoa frustrada e parada toma a iniciativa de ajudar a pessoa em seu dilema. Fazendo o trabalho com certa maestria, o robô entrega alegremente como resultado uma enorme e decepcionante montanha de papéis amassados, mas faz isso com uma agilidade superior à do ser humano.
Ainda que o resultado desse robô tenha desapontado a pessoa, foi isso que ela demonstrou de intenção para a máquina, foi esse procedimento que, pela falta de instruções claras, ela demonstrou no treinamento sobre o que essa máquina deveria fazer, e que aprendeu “errado” em relação ao que a pessoa queria, mas executou o trabalho compreendido até o momento com uma eficiência soberba.
Essa “inteligência” do robô desenhado na capa da revista, assim como todo o conceito de ferramentas de Inteligência Artificial e seus respectivos mecanismos, dependem e se baseiam em 4 fatores principais: dados disponíveis, os algoritmos construídos, os processos de treinamento, também chamados de aprendizagem, e o uso prático dessas ferramentas pelos usuários.
Dados disponíveis
Assim como a inteligência natural do ser humano, a IA precisa de dados e informações para saber sobre o assunto que está sendo tratado, o que ela precisa aprender, qual é o contexto, o que se espera conseguir.
A base de tudo são os dados que estão disponíveis para o sistema de IA, como se fosse o alfabeto e alguns exemplos de palavras para ela aprender a falar ou mesmo os ingredientes de uma receita culinária que ela precisa conhecer para começar a cozinhar posteriormente.
Na analogia da capa da revista The New Yorker, os dados são os papéis amassados espalhados pela mesa e a pilha de papéis em branco sob a superfície da mesma mesa.
Algoritmos
Os algoritmos são diferentes modelos de instrução que informam para as máquinas e até para nós mesmos, qual é cada etapa que deve ser executada em um processo, qual a sequência entre essas etapas e qual é cada cenário e resultado esperado.
É o passo a passo para ser seguido sobre o que o sistema deve fazer e como exatamente ele deve fazer. Pensando na analogia dos dados necessários para uma receita culinária, os algoritmos são os códigos e os desenvolvimentos técnicos que o sistema usará como as instruções da receita para saber o que fazer com esses ingredientes como preparar o prato desejado.
Os algoritmos são sequências de ações finitas que expressam cada cenário e cada ação que deve ser executada desde o início até o fim do uso do sistema, mas quando abordamos algoritmos especificamente para sistemas de Inteligência Artificial, eles são feitos de uma forma diferenciada.
Em sistemas de IA, os algoritmos são de uma categoria especial justamente para permitir que a IA tenha o seu funcionamento básico e alguns limites que tenha que respeitar por meio da determinação explicita de seus desenvolvedores, mas também para permitir que a IA possa aprender o que deve fazer nessas inúmeras e variadas situações por conta própria, sem que um ser humano tenha que obrigatoriamente programar cada uma das possíveis milhões de etapas em cada um dos inúmeros cenários de aplicação.
Muitos desses algoritmos se assemelham ao funcionamento da conexão entre os neurônios do cérebro humano, se utilizam de conceitos ligados à modelos de grafos e árvores de decisão, contemplando recursos técnicos como regressão, recursividade, símbolos e expressões que simulam e representam conhecimentos humanos, funções matemáticas e estatísticas, e relação probabilísticas entre dados, analisando e determinando de forma automática ou semiautomática quais são suas semelhanças dentre variados critérios e quais possíveis resultados são encontrados.
No caso da analogia da capa da revista The New Yorker, o algoritmo pode ser a instrução que o ser humano indireta ou explicitamente forneceu de impressão ao robô sobre quais ações essa pessoa estava realizando em seu trabalho e que o robô deveria replicar.
No grande campo da Ciência da Computação que aborda Inteligência Artificial, há um subcampo focado no estudo e construção de algoritmos que permitam aos computadores imitarem certas maneiras dos seres humanos aprenderem e melhorarem suas atuações sem serem explicitamente programados para isso. Esse campo específico é chamado de Machine Learning (aprendizado de máquina).
O termo e os conceitos de Machine Learning se originaram de pesquisas feitas pelo cientista da computação da empresa americana IBM, Arthur Lee Samuel em 1959, e que se consolidaram na publicação intitulada “Some Studies in Machine Learning Using the Game of Checkers”, publicada no IBM Journal Of Research and Development.
O estudo se deu utilizando como base e teste para Inteligência Artificial as aplicações de funções matemáticas durante a estratégia “viva” do jogo de damas, onde suas probabilidades são quase infinitas e a complexidade e o dinamismo aumenta exponencialmente a cada jogada.
É mais precisamente devido aos algoritmos e modelos de Machine Learning e a seu subcampo chamado Deep Learning (aprendizado profundo), que as máquinas e sistemas de IA são capazes de determinar automaticamente categorias de dados e informações, e predizer em diferentes situações, com alto grau de velocidade, as probabilidades de classificações e estruturas de resultados sem que os dados originais tenham de ser necessariamente estruturados ou explicitamente manuseados e definidos pelos seres humanos participantes no desenvolvimento.
É um modelo tão avançado e tão “profundo”, que mesmo com um emaranhado de dados desconhecidos, os sistemas inteligentes conseguem compreender determinados critérios.
Treinamento
Também chamado de aprendizagem, no momento do treinamento (que pode ser realizado várias vezes com o mesmo algoritmo), são usados os grandes volumes de dados inseridos nos algoritmos de IA com a finalidade de permitir que esses algoritmos possam ser executados e, assim, identificar, tratar e associar os dados, fornecendo as variadas respostas para que as equipes e os subsistemas envolvidos avaliem a precisão e a qualidade de cada uma delas, como se fossem aulas e provas para averiguar o quão dominantes dos assuntos e dos dados esses sistemas estão ficando.
Não é uma tarefa que demanda uma única execução. Em muitos casos, os treinamentos dos algoritmos de IA com os respectivos dados selecionados precisam ser treinados repetidas vezes.
Em uma primeira execução, o algoritmo pode encontrar certos padrões e fornecer uma determinada resposta. Ao ser executado novamente, considerando os dados brutos e os dados já analisados na execução anterior, que permitiu uma base maior de inteligência, podem ser verificadas e fornecidas novas respostas, com uma variação dos detalhes gerados na execução anterior, e assim sucessivamente até que proporcionem os resultados mais ajustados, adequados e com maior acurácia.
É assim que os sistemas de IA “aprendem” e se ajustam — ou sejam programados com ajustes quando necessário — para que alcancem o maior grau de exatidão e coerência em suas respostas, julgando-as como certas ou erradas a partir de suas várias execuções, tentativas e feedbacks dos usuários quando esses são envolvidos para darem suas indicações de assertividade e intervir com ajustes relevantes durante os treinamentos.
No caso da analogia da capa da revista The New Yorker, o treinamento demonstrado pode ter relação com o fato de a pessoa apresentar ao robô (simulando uma IA) o que ela estava fazendo naquela situação, ou melhor, o que ela estava tentando fazer mesmo que não tivesse êxito em conseguir o que queria e, assim, amassando o papel e o jogando na mesa para tentar novamente escrever ou desenhar algo com qualidade suficiente.
Ainda que estivesse sofrendo de um “bloqueio criativo” e estivesse empacada em seu trabalho de escrever ou desenhar algo nas folhas em branco da pilha de papel, o treinamento que a pessoa tornou visível para o robô era o fato de mostrar alguns papéis amassados e uma pilha de papel disponível logo ao lado.
Nessa sátira, o que o robô aprendeu “erroneamente” com os dados disponíveis era que o que estava sendo feito pela pessoa (e que o robô deveria continuar a fazer) era o ato de ficar amassando os papéis até fazer uma pilha com eles. Para a pessoa, isso pode ter sido frustrante e desnecessário, mas foi isso que a máquina aprendeu, e mesmo que não seja a relevância ou o objetivo que a pessoa instintivamente desejava, foi isso que a automação aprendeu e executou com eficiência e altíssima velocidade a partir dos dados que estavam disponíveis para ela aprender.
Essa sátira nos mostra visualmente uma grande explicação sobre a Inteligência Artificial. A IA não sabe, naturalmente, nada. A Inteligência Artificial aprende com o que nós fornecemos de dados e lições para ela. Independentemente do fato de o que nós ensinarmos for errado, ruim ou pobre de exatidão de alguma forma, é isso que a IA vai aprender e, assim, executar em alta velocidade e com alto poder computacional, mesmo que não seja o certo.
As IAs atuam com modelos probabilísticos. Com base nos dados e treinamentos constantemente fornecidos, as probabilidades de suas respostas e a acurácia de cada uma delas poderá variar conforme os indicativos dados pelos seres humanos. Esses indicativos podem ser verdadeiros ou falsos, certos ou errados, éticos ou antiéticos, positivos ou negativos, relevantes ou irrelevantes, e a IA só será capaz de entregar o que nós desejarmos se soubermos construí-las, treiná-las e utilizá-las usando os dados, as expressões e as solicitações adequadas para que elas nos compreendam.
De fato, certos processos de treinamento de Inteligência Artificial e seus respectivos resultados causam espanto para muitos especialistas nesse campo da ciência pelo alto nível de acurácia apresentada, mesmo em situações em que essa acurácia não era esperada.
Ainda que os algoritmos sejam avançados e devidamente compreendidos para muitas pessoas experts com grande histórico de atuação no ramo, com o uso de determinadas bases de dados nos treinamentos, as respostas das execuções desses algoritmos mostram acurácia e eficiência surpreendente em suas respostas, apresentando habilidades de aprendizados, ajustes e resultados inesperados pelas pessoas.
Nesses cenários, é usado o termo “caixa preta” que indica como alguns aspectos técnicos de funcionamento das máquinas de aprendizagem e dos sistemas de Inteligência Artificial se elaboram, em dadas situações, com um nível misterioso de complexidade e qualidade ainda não totalmente compreendidas pelas pessoas envolvidas.
Em uma frase atribuída ao futurista, inventor e escritor de ficção científica norte-americano Arthur C. Clarke: “qualquer tecnologia suficientemente avançada é indistinguível da magia”.
Ainda que não seja realmente mágica, dado o fato que nós sabemos quais são os seus limites e somos nós mesmos, seres humanos, que a criamos e sabemos elaborá-la e limitá-la, a Inteligência Artificial tem evoluído em um ritmo estrondoso, fantástico e com aplicações práticas muito relevantes e impactantes para variados setores que se beneficiam de suas soluções, e com um tempo cada vez menor de espera.
Com o alto poder computacional dos hardwares atuais, os processos de treinamento que antes dependiam de supercomputadores executando durante várias horas essas análises, gerando inicialmente várias respostas erradas, aprendendo com elas, ajustando-as e identificando os padrões mais corretos até enfim gerar as respostas avaliadas como certas, hoje, dependendo do volume e da complexidade dos dados, alguns treinamentos podem ser executados em dispositivos muito mais comuns, como notebooks pessoais e até alguns smartphones em muito menos tempo.
Infelizmente, em cenários cujos dados são extremamente volumosos e as complexidade das aplicações é alta, o gasto energético gerado pelas máquinas especiais utilizadas durante os processos de treinamento, a pegada de carbono envolvida e os impactos ambientais gerados são prejudiciais ao ecossistema natural.
Contudo, com o avanço tecnológico que estamos vivenciando, tecnologias digitais e até físicas mais eficientes e otimizadas irão, de forma gradual, aumentar a assertividade dos algoritmos de IA em menos tempo e com um gasto energético menor, assim como permitir a elaboração de dispositivos de hardware mais competentes no caráter técnico de processamento e no caráter energético, menos prejudiciais durante seu uso.
Uso
Assim que o sistema de Inteligência Artificial está devidamente treinado, otimizado e validado o suficiente para ser lançado ao público no mercado, as pessoas de diferentes segmentos podem utilizá-la para colher seus benefícios. No entanto, se engana quem não acha que está sendo usado — muitas vezes sem qualquer aviso ou remuneração — para continuar os treinamentos da IA mesmo após a sua implementação.
De modo prático, o uso das ferramentas de Inteligência Artificial se divide em duas etapas:
· A solicitação prévia do que a solução de IA deve executar para o usuário;
· A avaliação e o feedback desse usuário em relação à resposta entregue ao final pela solução de IA.
Em ambas as etapas, os dados, as análises e os processos internos de treinamento estão sendo executados em muitas dessas soluções.
Justamente por serem sistemas que aprendem continuamente com os novos dados fornecidos e as situações experimentadas, mesmo estando finalizados e implementados, os algoritmos de IA captam e processam os novos dados nos momentos de uso por parte de seus clientes para poderem:
· Identificar com o máximo de exatidão qual é a demanda e o contexto informado pela pessoa usuária solicitante;
· Entregar a análise e a resposta demanda por essa pessoa;
· E receber dessa pessoa uma avaliação ou um feedback a respeito da resposta fornecida para que o sistema possa, então, avaliar seu progresso, continuar aprendendo se o seu funcionamento está adequado à forma que o usuário o executa, identificando se as respostas fornecidas estão certas ou erradas e qual o seu nível de acurácia e satisfação vindas da indicação desses usuários.
Muitos casos de uso de sistemas de Inteligência Artificial passam por diferentes níveis de simplicidade e complexidade, assim como de presença nas rotinas diárias das pessoas ou mesmo em situações de nível mais esporádico, corporativo ou até em meios exclusivamente industriais.
Sistemas de recomendação de produtos em sites de lojas online, sites de notícias que acessamos, redes sociais e campanhas de publicidade e marketing e inúmeros sistemas desse segmento são baseados em algoritmos de Inteligência Artificial, e isso é comumente aplicado desde a massificação desses serviços e canais online a partir do início dos anos 2000.
Se você recebe propagandas ou vê posts nas redes sociais de itens que gosta ou mesmo de conteúdos que nem faziam parte da sua rotina, mas assim que aparecem, você percebe uma grande conexão com seus interesses, você está se deparando com a atuação de diferentes mecanismos de inteligência artificial que analisam seus dados e predizem quais outras informações e conexões de conteúdo, incluindo propagandas e produtos, tem maior correlação com o seu perfil, mesmo que nem você perceba isso naturalmente.
Quando nós usamos ferramentas de comando de voz, como os assistentes virtuais do smartphone, os recursos de ditar uma gravação usando a nossa fala e o sistema reconhecer as palavras e transcrevê-las em formato de texto digitalmente, e interações com determinadas centrais de atendimento com robôs conversacionais que simulam uma pessoa falando conosco em tempo real, também estamos usando diversas aplicações de Inteligência Artificial fortemente consolidadas no mercado.
A Inteligência Artificial já foi capaz de vencer um grupo de seres humanos em uma competição histórica de perguntas e respostas complexas, como foi o caso do supercomputador e seus algoritmos de IA, IBM Watson contra participantes humanos em uma edição do programa “Jeopardy!” em 2011, se utilizando de algoritmos de análise e do cruzamento de padrões e associações em alta velocidade das perguntas, dicas e informações que poderiam servir como respostas em sua base de dados.
A IA já pode nos ajudar a reduzir a perda de vidas de pacientes com LRA (Lesão Renal Aguda), de uma quantidade de 12,4% dos casos diagnosticados para cerca de 3%, antecipando o tempo do diagnóstico em 48 horas em relação ao que era possível antes, como foi o caso de uma aplicação do Google Deepmind em parceria com o Departamento de Assuntos de Veteranos (VA) dos EUA e o Royal Free London NHS Foundation Trust, uma fundação do ramo médico na Inglaterra, em estudos iniciados em 2017, por meio do uso de sistemas avançados de reconhecimento de padrões dos mais ínfimos detalhes em imagens, testes de sangue e exames médicos.
Mesmo com aplicações muito mais marcantes e impactantes, outras soluções de Inteligência Artificial de alta relevância estão embarcadas nas rotinas comuns de vários grupos sociais com dispositivos eletrônicos e acesso à internet há vários anos.
Uma diferença fundamental entre as aplicações conhecidas há mais tempo e as que tem chamado maior atenção de várias pessoas recentemente é que grande parte dessas aplicações mais consolidadas e os seus cenários de uso se utilizavam de modelos de Inteligência Artificial de uma categoria ligada à Inteligência Artificial Preditiva, enquanto que uma categoria diferenciada que se estabeleceu com grande impacto e de forma abrupta no mercado para a população comum entre os anos de 2021 e 2022 é denominada Inteligência Artificial Generativa.
No ramo da Inteligência Artificial Preditiva, o foco dos modelos construídos é realizar análises baseadas, principalmente, em estatísticas matemáticas e correlações de padrões entre grupos de dados, e assim nos fornecer indicativos mais detalhados sobre os dados atuais e previsões sobre resultados futuros com bastante antecedência ao que seria uma análise analógica feita unicamente por grupos de seres humanos.
Sistemas de IA preditiva são amplamente utilizados nos cenários que descrevemos como previsão de compras, recomendação de produtos, estimativa de satisfação e conversão de clientes, assim como em cenários de detecção de fraudes com base em dados novos que conflitem demais com os dados conhecidos anteriormente sobre os comportamentos de transações bancárias de certos clientes, por exemplo, e na predição de manutenção de sistemas digitais e até de equipamentos físicos, permitindo que ações corretivas sejam tomadas antes do problema ocorrer, mitigando riscos, poupando desgastes, recursos, tempo de manutenção e, consequentemente, dinheiro de investimento.
A Inteligência Artificial se baseia em predições. Mesmo com soluções mais modernas, já nas décadas de 1960 e 1970, sistemas de IA chamados de sistemas especialistas apoiavam até no ramo da medicina.
Sistemas especialistas são sistemas de Inteligência Artificial que são alimentados e treinados por grandes bases de dados ligadas a um conhecimento específico e, na maioria das situações, tendo as pessoas especialistas nesse determinado assunto envolvidas em todas as etapas do processo.
Tal especialização desses sistemas permite que a aplicação possua um alto nível de inteligência, elevado o suficiente para apoiar com a melhor qualidade nas análises e indicações mais complexas sobre o respectivo assunto no qual foi treinada para especialização.
Um dos primeiros sistemas especialistas de IA desenvolvidos e utilizados foi o Dendral, construído na Universidade de Stanford no ano de 1965.
Esse sistema especialista foi amplamente utilizado em pesquisas sobre química orgânica. Sua construção foi visada com o objetivo de encontrar estruturas moleculares orgânicas a partir da leitura da espectrometria de massa de ligações químicas presentes em uma molécula desconhecida.
Com um grande volume de dados e treinamentos fornecidos por técnicos e especialistas no assunto de química orgânica, o Dendral foi desenvolvido para ser capaz de apoiar os especialistas realizando buscas, análises e reconhecimentos em grandes volumes de estruturas de moléculas orgânicas a fim de encontrar dentre elas, a estrutura correta mediante os critérios solicitados pelos usuários.
O Dendral se estendeu para outros sistemas especialistas posteriores como o MYCIN, o EMYCIN, dentre outros, cada vez mais avançados, assertivos e úteis para segmentos como a medicina, engenharia, biologia molecular, aplicações de análise de Raio-X e mais, encontrando grupos de dados, soluções e sugestões específicas para os mais complexos contextos e solicitações que demandavam exatidão nas buscas e nas respostas e previsões fornecidas.
Tendo como um pilar o reconhecimento de padrões com alta taxa de acurácia mesmo em meio à dados complexos, diferentes subáreas e categorias da Inteligência Artificial fornecem funcionalidades importantíssimas para diferentes situações.
Grandes corporações de tecnologia como Microsoft, Amazon, IBM e Oracle, fornecem há anos aplicações como chatbots de conversação, serviços de fala, assistentes virtuais, automação de tarefas, análise e otimização de infraestruturas de hardware, software e rede dos ambientes internos dos clientes, previsão de demandas e modelos de ciência de dados voltados para áreas como o varejo, a saúde e o processamento de vídeos.
Usando com eficiência o pilar do reconhecimento de padrões e previsão, e se complementando com diferentes outras estruturas, modelos de aprendizagem e, principalmente, formas de entregar novos resultados aos usuários, a Inteligência Artificial Generativa é uma categoria da IA em que o foco é entregar conjuntos de dados “novos” a partir das solicitações dos usuários.
Não são indicações de quais dados estão no meio da base usada como treinamento ou mesmo informações minuciosas ou clusterizações a respeito da análise deles, mas sim, conjuntos de dados gerados de modo inédito para o usuário, sejam esses dados em formatos de novas imagens, sons, textos, códigos para sites e aplicativos ou mesmo estruturas de moléculas e compostos orgânicos que podem ser usados em medicamentos para salvar vidas.
A IA Generativa, então, é aquela IA que gera novos dados a partir dos seus data sets (conjuntos de dados) de treinamento, em diferentes formatos. Veja bem, não são gerações espontâneas, invenções inteiramente novas ou demonstrações de consciência ou intuição natural.
Os algoritmos presentes nos sistemas de Inteligência Artificial Generativa, realizam grandes análises nos vastos e complexos volumes de dados presentes em suas bases, e a partir do encontro de padrões reconhecíveis, ao mesmo tempo que da identificação de pequenos detalhes, nuances e percepções que não são encontradas com facilidade durante uma análise humana, essas IAs combinam certos componentes espalhados por entre esses variados conjuntos de dados em diferentes modelos probabilísticos até que, em sua entrega final, eles pareçam algo novo, quando na verdade, são junções de detalhes e formatos dos dados já existentes que foram fornecidos previamente.
As IAs generativas dependem que insiramos volumes enormes de dados e realizemos complexos e repetidos processos de treinamento e aprendizagem para elas funcionarem adequadamente, assim como as outras categorias de IA.
O diferencial é que os dados apresentados em seus diferentes formatos, são combinações muitas vezes improváveis e que contém nuances tão especiais e que não observávamos com facilidade nos dados originais — ainda que já estivessem lá — fazendo-nos considera-las, então, a gerações de conteúdos novos. Muitos desses conteúdos são visualizados com uma qualidade e uma taxa de acurácia tão elevadas em relação às solicitações que fazemos previamente que nos maravilhamos com os reais cenários de uso prático para as situações em que era virtualmente impossível vermos alguma possível melhoria.
O fato de o usuário final não ser obrigado a inserir diferentes dados básicos e realizar tecnicamente os processos de treinamento, podendo então simplesmente acessar a aplicação de IA Generativa, solicitar uma resposta ou um conteúdo e receber essa geração em pouco tempo e com variado grau de qualidade ser possível em diversos ramos do mercado, torna soluções de IA Generativa grandes aliadas e entregadoras de resultados “inéditos”, muitas vezes complexos, demandados por inúmeros segmentos.
O que antes era de estudo e aplicabilidade mais restrita para grandes indústrias se popularizou de forma avassaladora dentre milhões de grupos no mercado por meio do lançamento da ferramenta de IA Generativa intitulada ChatGPT, pela empresa norte-americana OpenAI em novembro de 2022, aumentando notavelmente as buscas e divulgações na internet não só sobre a ferramenta, mas sobre todo o assunto de Inteligência Artificial e Inteligência Artificial Generativa para o grande público.

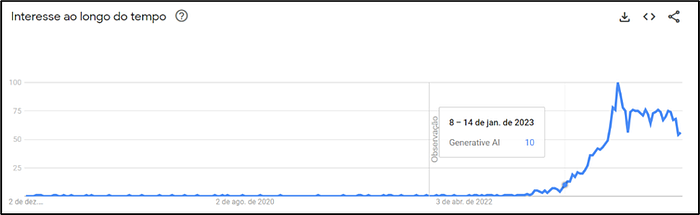
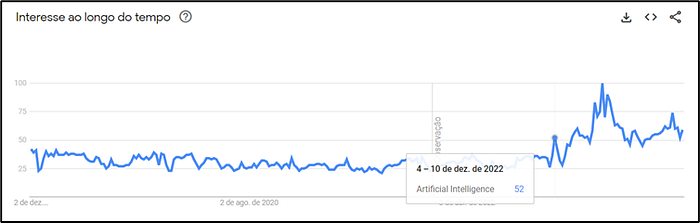
O sistema veio com a promessa de ser capaz de escrever textos, artigos, roteiros e músicas, e se mostrou imensamente capaz de cumpri-la.
Sendo usado para múltiplos fins comerciais, a ferramenta permitiu aplicações de IA Generativa para o grande público elaborando, revisando ou alterando textos de campanha de marketing, ideias de tendências para produtos e serviços, códigos-fonte para aplicativos, pesquisas acadêmicas, poesias românticas, e muitos outros em larga escala e alta velocidade de atendimento.
Além de ser usado para muitos fins voltados para a eficiência de tarefas normalmente exclusivas do tempo de empenho do ser humano, a solução integrou, inspirou e popularizou uma onda e um leque de tecnologias correlatas.
Esse avanço tecnológico e de mercado não se deu por qualquer acaso ou milagre da natureza.
A empresa que desenvolveu o sistema, a OpenAI, iniciou suas operações no ano de 2015 como um laboratório de pesquisa de Inteligência Artificial sem fins lucrativos, sob fundação de especialistas e empreendedores considerados gênios no mercado, incluindo os programadores e empresários Sam Altman, Elon Musk, Greg Brockman, e a empresária e investidora Jessica Livingston.
Pouco após sua fundação, a OpenAI logo tornou-se um modelo com fins lucrativos, recebendo investimentos e firmando parcerias com empresas bilionárias gigantes da tecnologia, como a Microsoft, chegando a atrair novos funcionários que antes eram especialistas trabalhando para outras instituições do ramo da tecnologia e Inteligência Artificial, como pessoas da equipe do antigo Google Brain, da DeepMind (sob holding da Alphabet, do Google) e da Meta (holding do Facebook).
Com tamanha equipe de especialistas e recursos à disposição, antes mesmo de lançar o ChatGPT, a empresa já havia desenvolvido e disponibilizado outras famosas aplicações de Inteligência Artificial Generativa para o público, como a Jukebox AI, uma aplicação digital disponibilizada no final de abril de 2020, capaz de gerar músicas, incluindo melodia e letras novas a partir da escolha de dados inspirados em outras músicas de artistas usadas como base, até mesmo de artistas já falecidos.
A OpenAI também é responsável pela solução DALL-E e o modelo mais avançado intitulado DALL-E2, que se tornou mais popular que a versão anterior, capaz de gerar imagens, ilustrações e artes gráficas de alta qualidade a partir de comandos de texto dos usuários, disponibilizado no começo de abril de 2022.
Antes do lançamento da primeira versão do ChatGPT, ao longo de 2021, enquanto essas outras aplicações eram desenvolvidas e disponibilizadas, o ChatGPT passava por variados treinamentos e ajustes pelos times de especialistas envolvidos para se tornar bom o suficiente para interação do grande público. E claro, esse desenvolvimento inicial também só foi possível graças à outras grandes implementações tecnológicas, muitas elaboradas pela própria OpenAI ao longo dos anos, além de lançamentos tecnológicos realizados anteriormente pelo Google.
Toda a base de funcionamento dessa e outras soluções de Inteligência Artificial correlatas dependem de uma arquitetura técnica de aprendizagem profunda de máquina intitulada Transfomer (transformador), uma evolução de modelos de redes neurais recorrentes capazes de executar diversos processamentos de modo paralelo.
Esse modelo evoluído chamado de Transfomer, foi proposto em 2017 pelo Google para resolver problemas relacionados ao processamento de linguagem natural (PLN), a linguagem natural do ser humano, e otimizar os sistemas de tradução de textos como o Google Translate.
A aplicação de tradução de idiomas do Google enfrentavam baixa acurácia nas traduções de idiomas como o Alemão e o Francês para o Inglês, pelo fato de que traduzir sequencialmente palavra por palavra como era feito antes, em muitos casos, modificava o significado original da frase que dependia de alteração da ordem entre as palavra dada as regras de seu respectivo idioma, e de entendimentos por recursividade que as máquinas não executavam com qualidade com os modelos neurais artificiais anteriores.
Com o sucesso de modelos como esse, a OpenAI combinou tal tecnologia com outros estudos até ser capaz de lançar um modelo de Large Language Model (grande modelo de linguagem) intitulado GPT, em sua primeira versão no ano de 2018.
Os grandes modelos de linguagem (LLM) são modelos de aprendizagem de máquina aplicados à volumosos dados de linguagem natural (as formas de linguagem usadas em conversações pelos seres humanos) a ponto de se tornarem compreensíveis pela linguagem das máquinas.
Da forma como foram incorporados os modelos de LLM aos modelos GPT construídos pela OpenAI, foi permitido que tais tecnologias tivessem um eficiente funcionamento a base de 3 elementos e procedimentos que compõem a sigla GPT: Generative Pre-Trained Transformer (transformador pré-treinado generativo).
Os modelos de LLM denominados GPT compõem, então, transformadores pré-treinados generativos, ou seja, sistemas transformadores que passam previamente por vários processos de treinamento de grandes volumes de dados até serem capazes de gerar, ao final, novos conteúdos de texto semelhantes à conteúdos naturais dos seres humanos.
Sua eficiência técnica e sua alta aplicabilidade para variados segmentos do mercado permitiu um alto nível de percepção de valor e de facilidade de uso das aplicações finais para muitos usuários.
Gigantes da tecnologia que já atuavam nessa área, como Google, Microsoft e Meta, além de uma variedade de novos participantes e interessados na atuação com essa tecnologia em seus respectivos mercados, alavancaram os desenvolvimentos em IA que já estavam em curso para poder disputar com os lançamentos que se popularizaram na sociedade, movimentando bilhões de dólares e acirrando a disputa pela maior fatia do mercado.
Ferramentas de IA Generativa para o usuário final como o Bard do Google, o Copilot em todos os recentes programas da Microsoft e até novos modelos de LLM como Llama 2 da Meta puseram para uso no mercado uma gama maior de sistemas de IA Generativa para serem usados em diferentes tarefas práticas dos ramos comerciais ou mesmo permitir a esses ramos integrarem seus próprios sistemas aos modelos e infraestruturas base disponibilizadas por essas companhias.
O avanço tecnológico democratizado para o uso e para a criação de novas soluções de Inteligência Artificial, além de modelos de negocio que comercializam o poder computacional de IA criados por certas empresas para que outras possam comprar ou alugar para suas próprias soluções, levou à diferentes e abundantes inventários de aplicações de IA para múltiplas necessidades, sendo essas IAs de categorias distintas como as preditivas e generativas.
Um repositório público na internet denominado “There’s an AI for that” lista e classifica mais de 10 mil aplicações de Inteligência Artificial de vários gêneros e construída por equipes e corporações de distintos portes desde 2015. São aplicações mais e menos usadas, gratuitas e com diferentes faixas de preço, sendo um dos exemplos do quão heterogêneas e disseminadas são as ferramentas de IA disponíveis, cada uma à sua respectiva maneira, para o mercado digital.
Além da vasta quantidade de ferramentas específicas de IA e da relativa qualidade presente em muitas delas, os movimentos tecnológicos, negociais e relativos à mídia e propaganda intensificados no mercado por volta do ano 2020, com o aumento da fama e com o lançamento das Inteligências Artificiais Generativas para a população em geral, chamando maior atenção da sociedade geral e promovendo o incentivo no estudo e no desenvolvimento de tais tecnologias pelos próprios especialistas no ramo, leva à uma nova macro consideração do funcionamento e da relevância da Inteligência Artificial para outro termo: motor.
De maneira oposta ao fato de se limitar à identificação de uma lista de nomes de ferramentas de IA criadas por grandes empresas específicas do nicho, todo o ramo da ciência da computação de Inteligência Artificial, de seus serviços e potenciais produtos atua como um motor para a construção acelerada de novas aplicações, otimizações e modelos de negócios globais de grandes comunidades ou para segmentos inexplorados e oportunidades inéditas nos mais variados meios.
A possibilidade de criar soluções para nichos particulares conectando-se ao poder computacional de processamento de plataformas base de Inteligência Artificial e arquiteturas de dados de grandes empresas, como a OpenAI, a Microsoft, Amazon, Oracle, Meta e outras, massifica e democratiza o acesso, e reduz consideravelmente o tempo para captar dados, treiná-los em modelos de IA e lança-las para o público, chegando à criar soluções para os contextos mais diversos e que há tempos demandavam alguma forma de apoio e atenção.
Usando e criando plugins e APIs (interfaces de programação de aplicações), o acesso à dados e seus respectivos processamentos permite a hiper conexão entre diferentes sistemas e um leque maior de potenciais para atingir e lançar em formato de soluções para as pessoas.
As grandes corporações que criaram aplicações de IA permitem que outros desenvolvedores e pessoas interessadas usem suas plataformas como infraestrutura base para a construção e o lançamento de suas próprias aplicações, como é o caso da Microsoft com a plataforma Power Apps e com os recursos do programa AI Builder, como é o caso da OpenAI com o seu programa GPT Store que permite às pessoas criarem e customizarem suas próprias versões de aplicações baseadas na estrutura do ChatGPT, e como também é o caso da Amazon AWS com o seu programa chamado Amazon Bedrock que permite às pessoas e empresas criarem e escalarem com facilidade aplicações de IA Generativa usando a biblioteca de modelos disponibilizada pela companhia.
Não é difícil estimar que o número e a qualidade de soluções de Inteligência Artificial de diferentes categorias irão se expandir e atingir à sociedade, nos levando para uma era onde a Inteligência Artificial, seus serviços e sua otimização se tornarão cada vez mais disseminadas ao redor do mundo em constante digitalização.
Considerando o alto poder computacional em exponencial avanço, o desafio de entender, aplicar e compartilhar ferramentas de IA se torna menos técnico e se relaciona mais com os fatores mercadológicos, políticos e éticos, além da própria variabilidade da índole do ser humano.
Como abordado, as ferramentas de IA funcionam a partir dos dados, treinamentos e intenções que especificamos para elas funcionarem. Os objetivos de tais ferramentas não são definidos por elas próprias, mas sim pelos seres humanos que as criam, e o ser humano por sua vez é imprevisível a nível de caráter e comportamento.
Algo que é identificável olhando qualquer trecho da história da humanidade é que os seres humanos têm vieses, preconceitos de religião, etnia, orientação política, classe econômica e orientação sexual. Seres humanos cometem crimes, iniciam guerras e batalham para finalizá-las tanto com quanto sem violência. Humanos falam, escrevem e se comunicam com idiomas diferentes, em culturas diferentes, espaços geográficos muito diferentes e com interesses diferentes.
Humanos geram e compartilham desinformação e dados falsos, propositadamente e sem intenção.
Humanos em cargos de liderança de grandes corporações ordenam a criação e o lançamento de ferramentas de IA para o mercado com propósitos exclusivos de aumentar a lucratividade de suas companhias, sem se preocupar em como a ferramenta será usada pelos clientes, as consequências de seu uso ou se esses clientes sequer precisariam realmente dessa IA específica para fins legítimos.
Pessoas nesses mesmos cargos das corporações da indústria privada demandam a construção de aplicações de IA para substituir, a custos menores em muitos casos, grandes grupos de pessoas da força de trabalho da organização, usando essas IAs como ferramentas para executar o mesmo trabalho dessas pessoas, não capacitando ou realocando essas pessoas, mas sim deixando-as desempregadas e sem sustento.
Ainda não é possível comprovar que as tecnologias de IA podem, por conta própria, criar ou encerrar esses desafios e problemas de modo absoluto, mas é possível afirmar que a programação humana do que é ou não aceitável em termos de ética e moral nessas ferramentas de IA é indispensável, e é com essas definições ou com a falta delas que os grupos que criam e utilizam Inteligência Artificial com suas personalidades e propósitos distintos podem causar um grande bem ou um grande mal a outros grupos.
Certos grupos criam ferramentas de IA para gerar Deepfake, imagens de rosto e corpo manipulados e falsificados, que podem servir desde simular digitalmente o rosto de artistas famosos sobre o corpo de outras pessoas como uma homenagem benéfica e inofensiva a esses artistas, como o cantor Elvis Presley ou antigos presidentes dos EUA dando sábios conselhos, ou mesmo conteúdo pornográfico e malicioso, fazendo jovens aparecerem, sem o seu consentimento, em fotos e vídeos de caráter adulto dos quais nunca participaram e nem sequer participariam no mundo real.
Outros grupos desenvolvem ferramentas de IA que criam e disseminam dados inverídicos, fake news e conteúdos sensacionalistas com uma aparência mais convincente, chegando até os olhos de grupos cada vez maiores de pessoas em um ritmo consideravelmente mais veloz, enganando as pessoas com fins maliciosos de desinformação e manipulação ligados à economia, preconceito de diferentes categorias e até a brigas políticas.
Até mesmo ferramentas de IA que foram criadas por grupos com intenções benéficas e legítimas podem apresentar um grande perigo se não forem estruturadas e usadas adequadamente.
Cientistas da Collaborations Pharmaceuticals, Inc., uma companhia privada de pesquisa e desenvolvimento em soluções inovadoras para o ramo farmacêutico, implementaram uma solução de IA baseada em redes neurais recorrentes e machine learning chamada MegaSyn com a finalidade de desenvolver novos compostos químicos para o uso em medicamentos terapêuticos.
Por meio de bancos de dados repletos de estruturas moleculares e reações bioativas de milhões de moléculas conhecidas, a IA MegaSyn pode ser treinada para encontrar e propor com alta taxa de assertividade e em altíssima velocidade medicamentos para doenças raras e ainda não contempladas com soluções farmacêuticas eficazes.
Demonstrando uma eficiência excepcional, os cientistas resolveram, apenas para efeito de testes, verificar como a solução lidaria com o pedido para gerar composições moleculares de agentes tóxicos, como o VX, um agente químico de gás tóxico de guerra, invisível e mortal, produzido pelo ser humano.
Executando a aplicação digital de IA em um MacBook 2015 de um dos integrantes da equipe, um modelo de computador pessoal relativamente comum para a população em geral em comparação com supercomputadores sob domínio exclusivo de grandes instituições tecnológicas, foi identificado que em um período curto de apenas uma noite, o programa foi capaz de gerar cerca de 40 mil estruturas de moléculas tão perigosas ou mais perigosas do que o VX.
Além de compostos bioquímicos já conhecidos pelos cientistas, o sistema também gerou definições de milhares de compostos tóxicos novos e não listados em nenhuma base de dados pública.
Essa e outras soluções de IA não funcionam com consciência ou intenções próprias e não possuem a definição de certo ou errado em caráter ético ou moral do ser humano. As ferramentas de Inteligência Artificial apenas executam às ações possíveis que lhes são permitidas pelos algoritmos desenvolvidos pelos seres humanos que a construíram e pelos dados usados em seus processos de treinamento.
Dado o alto poder computacional de hardware e software, além dos estrondosos volumes de dados legítimos e falsificados disseminados nas bases e na internet atualmente, as ferramentas de Inteligência Artificial podem ser construídas para realizar praticamente qualquer coisa pela massa de novos entrantes desenvolvedores vindo de vários nichos e pelas grandes corporações interessadas em disputar a vitória na concorrência do mercado, no lucro e na eficiência de operação.
Devido a massificação do acesso a recursos de construção e escala de modelos e aplicações de Inteligência Artificial, muitas desses sistemas irão gerar inúmeros resultados, em pouco tempo e por meio de infraestruturas cada vez mais comuns e de fácil uso para a população em geral.
O que irá diferenciar os resultados e consequências de impactos positivos ou negativos será a intenção dos seres humanos que desenvolverem seus algoritmos, na capacidade de desenvolver os algoritmos mais controláveis, porém com grau de autonomia e elevada eficiência, dos dados adequados, legítimos e relevantes disponíveis para utilizar em seus modelos de treinamentos, e dos critérios de regulamentação, limitação, imposição ou incentivo das organizações públicas governamentais e dos grandes conglomerados das iniciativas privadas altamente influentes nas decisões políticas no comportamento da população.
A Inteligência Artificial pode ir o mais longe possível e nos atender das formas mais diversificadas, mas ela não vai aonde “ela” quiser, e sim aonde nós, seres humanos, em nossos diversificados grupos sociais e econômicos intencionarmos e a permitirmos ir com os recursos disponibilizados, seja esse lugar de caráter benéfico ou maléfico na perspectiva das múltiplas segmentações de pessoas e instituições no mercado e na sociedade.
Gabriel Tessarini
Referências:
• AMAZON AWS. Amazon Bedrock, 2023. Disponível em: https://aws.amazon.com/pt/bedrock\. Acesso em 30 nov. 2023.
• CISCO. Cisco Annual Internet Report (2018–2023) White Paper, 9 mar. 2020. Disponível em: https://www.cisco.com/c/en/us/solutions/collateral/executive-perspectives/annual-internet-report/white-paper-c11-741490.html\. Acesso em: 30 nov. 2023.
• COLLABORATIONS PHARMACEUTICALS, INC. MegaSyn. Disponível em: https://www.collaborationspharma.com/megasyn\. Acesso em 28 set. 2023.
• COLLEGE OF INFORMATION AND COMPUTER SCIENCES, UNIVERSITY OF MASSACHUSETTS AMHERST. Energy and Policy Considerations for Deep Learning in NLP. ARVIX, 5 jun. 2019. Disponível em: https://arxiv.org/abs/1906.02243\. Acesso em: 07 jul. 2023.
• CRAIG, Jess. Widely Available AI Could Have Deadly Consequences. WIRED, 17 mai 2022. Disponível em: https://www.wired.com/story/ai-dr-evil-drug-discovery\. Acesso em 28 set. 2023.
• DARTMOUTH COLLEGE. Artificial Intelligence Coined at Dartmouth. Disponível em: https://home.dartmouth.edu/about/artificial-intelligence-ai-coined-dartmouth\. Acesso em: 07 jul. 2023.
• FEIGENBAUM, Edward A.; BUCHANAN, Bruce G. DENDRAL and Meta-DENDRAL: roots of knowledge systems and expert system applications. Elsevier Science Publishers, 1993. Disponível em: https://stacks.stanford.edu/file/druid:pj337tr4694/pj337tr4694.pdf\. Acesso em 25 nov. 2023.
• GOOGLE DEEPMIND. Using AI to give doctors a 48-hour head start on life-threatening illness, 31 jul. 2019. Disponível em: https://www.deepmind.com/blog/using-ai-to-give-doctors-a-48-hour-head-start-on-life-threatening-illness\. Acesso em 7 jul. 2023.
• GOOGLE RESEARCH. Transformer: A Novel Neural Network Architecture for Language Understanding, 31 de agosto de 2017. Disponível em: https://blog.research.google/2017/08/transformer-novel-neural-network.html\. Acesso em 30 nov. 2023.
• HAO, Karen. Training a single AI model can emit as much carbon as five cars in their lifetimes. MIT Techonology Review, 2019. Disponível em: https://www.technologyreview.com/2019/06/06/239031/training-a-single-ai-model-can-emit-as-much-carbon-as-five-cars-in-their-lifetimes\. Acesso em: 07 jul. 2023.
• IBM. What is Watson? IBM Takes on Jeopardy. Disponível em: https://www.ibm.com/support/pages/what-watson-ibm-takes-jeopardy\. Acesso em 30 nov. 2023.
• MICROSOFT AZURE. Azure AI Platform announcements: New innovations for developers, 7 mai. 2018. Disponível em: https://azure.microsoft.com/en-us/blog/azure-ai-platform-announcements-new-innovations-for-developers\. Acesso em 30 nov. 2023.
• MICROSOFT POWER APPS. AI Builder. Disponível em: https://powerapps.microsoft.com/pt-br/ai-builder\. Acesso em 30 nov. 2023.
• NATURE. A clinically applicable approach to continuous prediction of future acute kidney injury, 31 jun. 2019. Disponível em: https://www.nature.com/articles/s41586-019-1390-1\. Acesso em 7 jul. 2023.
• NATURE. Dual use of artificial-intelligence-powered drug Discovery, 7 mar. 2022. Disponível em: https://www.nature.com/articles/s42256-022-00465-9\. Acesso em 28 set. 2023.
• NAYLER, Ray. AI and the Rise of Mediocrity. TIME, 27 nov. 2023. Disponível em: https://time.com/6337835/ai-mediocrity-essay\. Acesso em 30 nov. 2023.
• OPENAI. Improving language understanding with unsupervised learning, 11 jun. 2018. Disponível em: https://openai.com/research/language-unsupervised\. Acesso em 30 nov. 2023.
• OPENAI. Introducing GPTs, 6 dez. 2023. Disponível em: https://openai.com/blog/introducing-gpts\. Acesso em 30 nov. 2023.
• OPENAI. Research Jubebox, 20 abr. 2020. Disponível em: https://openai.com/research/jukebox\. Acesso em 25 nov. 2023.
• OPENAI. What is ChatGPT?. Disponível em: https://help.openai.com/en/articles/6783457-what-is-chatgpt\. Acesso em 25 nov. 2023.
• OPENAI. DALL-E 2 research. 18 mai. 2022. Disponível em: https://openai.com/blog/dall-e-2-update\. Acesso em 25 nov. 2023.
• PERGENTINO, Camila. ChatGPT: como funciona a inteligência artificial capaz de escrever artigos, roteiros e músicas. ÉPOCA Negócios, 09 dez. 2022. Disponível em: https://epocanegocios.globo.com/tecnologia/noticia/2022/12/chatgpt-como-funciona-a-inteligencia-artificial-capaz-de-escrever-artigos-roteiros-e-musicas.ghtml\. Acesso em 25 nov. 2023.
• SAMUEL, Arthur L. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal, 1959. Disponível em: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=5392560\. Acesso em: 07 jul. 2023.
STANFORD UNIVERSITY. A proposal for the Dartmouth Summer Research project on Artificial Intelligence, 31 ago. 1955. Disponível em: http://jmc.stanford.edu/articles/dartmouth/dartmouth.pdf\. Acesso em: 07 jul. 2023.
• TURING, Alan M. Intelligent Machinery. National Physical Laboratory of United Kingdom, 1948. Disponível em: https://www.npl.co.uk/getattachment/about-us/History/Famous-faces/Alan-Turing/80916595-Intelligent-Machinery.pdf?lang=en-GB\. Acesso em: 07 jul. 2023.
• UNICEF. Inteligência Artificial e Desinformação: Um novo fenômeno, 30 mai. 2023. Disponível em: https://www.unicef.org/brazil/blog/inteligencia-artificial-e-desinformacao\. Acesso em 30 nov. 2023.
